
Thinking of how search engine performs when generating information based on queries done by users can be considered as complex, a complicated one since there are millions of web pages that need to be known by its spiders before it can generate the most comprehensive, relevant query-results. However, this time, I'll try to explain it in the most simple way as possible.
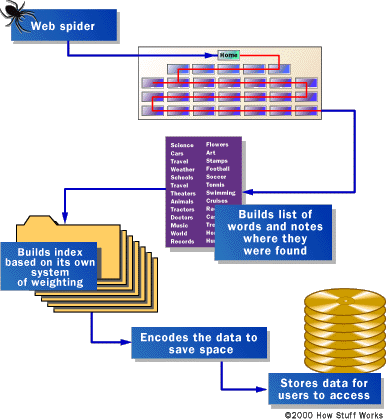
Search Engine works through the help of its spider—this is a set of algorithm/program that systematically works for website data gathering. It works to gather innformation necessary to meet what a search engine user is looking for.
Here's how it works...
Spider ( Crawler)--as I have said, spider is a set of algorithm or program that collects/follows website information through links. Spider crawls every web page available in the web and gather data from it;
The spider goes back to its home and with it are the data it collects. The information a spider collects is stored/indexed in search engine's database;
Once a query is done ( by search engine user), search engine compares the user's inputted data with the information indexed in its database—looking for the most relevant information;
Search Engine then generates information found in the search engine's database—those that match to the user's query and then rank them according to its authority or relevance.
That's how search engine works.
No comments:
Post a Comment